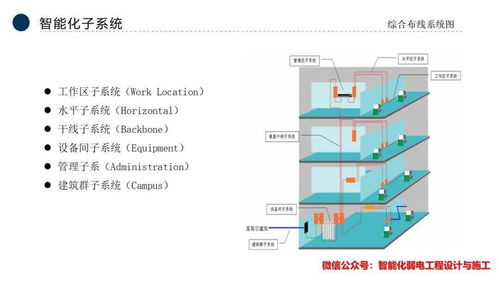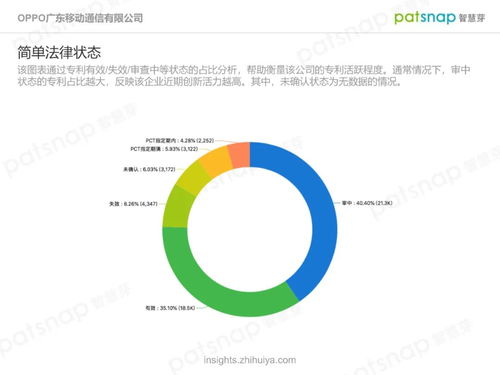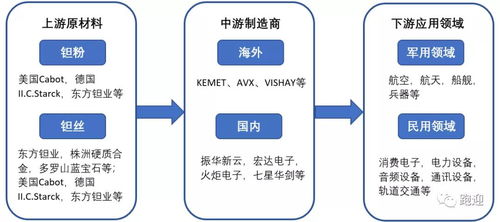
引言
在当今数据驱动的时代,大规模实时分析平台已成为企业决策的核心支撑。ClickHouse,作为一款开源的列式数据库管理系统,凭借其卓越的查询性能,在众多分析场景中脱颖而出。其高性能的基石之一,便是其核心存储引擎——MergeTree。本文将深入解析 MergeTree 存储引擎的读路径(Read Path)原理,并探讨其在高性能分析平台(MK分析平台)中的关键作用与优化实践。
一、MergeTree 存储引擎概述
MergeTree 是 ClickHouse 中最重要、最复杂的表引擎。它并非单一引擎,而是一个引擎家族,但其核心设计思想一致:
- 数据分区(Partitioning):按时间(通常是日期)或其他维度将数据分割成不同的部分(Partition),便于管理和剪枝。
- 数据片段(Data Part):每个分区内,数据被进一步切分为多个不可变的“数据片段”。每个片段是一个物理目录,包含数据文件(.bin)、索引文件(.idx)、标记文件(.mrk)等。
- 合并(Merge):后台线程会定期将多个小的、旧的数据片段合并成更大的、新的片段,以此优化存储和查询性能。这也是“MergeTree”名称的由来。
读路径,即从磁盘读取数据并返回给查询结果的全过程,其效率直接决定了查询的响应速度。
二、MergeTree 读路径核心机制解析
读路径的核心目标是:用最少的I/O,读取最少的数据,完成查询。其实现依赖于多级索引和高效的数据扫描。
1. 索引结构:跳数与粒度
- 主键索引(Primary Index):存储在
.idx文件中。它并非传统B-Tree索引,而是一种“稀疏索引”。它不会为每一行建立索引项,而是每隔固定的数据行(由index_granularity参数定义,默认8192行)记录一次主键的值和对应数据块的起始位置。这使得索引非常小,常驻内存,能快速定位到可能包含目标数据的数据块范围。 - 数据标记(Data Mark):存储在
.mrk文件中。它是连接稀疏索引与压缩数据块的桥梁。每个索引粒度(Granule)对应一个标记,记录了该粒度数据在压缩数据文件(.bin)中的偏移量和解压后的偏移量。查询时,通过主键索引找到相关的标记,再通过标记精准定位到需要读取的压缩数据块。
2. 读路径执行流程
对于一个典型的查询(如SELECT * FROM table WHERE date = '2023-10-01' AND id > 1000):
- 分区剪枝(Partition Pruning):首先利用
WHERE条件中的分区键(如date),直接过滤掉无关的分区目录,大幅减少需要扫描的数据量。 - 主键索引剪枝(Primary Index Lookup):在目标分区内,利用主键索引进行二分查找,快速确定哪些索引粒度(Granules)可能包含满足
id > 1000条件的数据。这一步在内存中完成,极其高效。 - 标记读取与数据块定位:根据索引筛选出的粒度,读取对应的数据标记(.mrk),获取到磁盘上具体需要读取的压缩数据块位置。
- 并行数据读取与解压:ClickHouse 会发起多个I/O请求,并行读取筛选出的压缩数据块。数据按列存储,因此只需读取查询涉及的列。读取后,数据在内存中解压。
- 向量化执行(Vectorized Processing):解压后的数据以列式“向量”(数组)的形式,送入执行引擎进行过滤、计算等操作。CPU利用SIMD指令进行批量处理,极大提高了数据处理吞吐量。
- 结果返回:将最终结果组装返回。
三、在MK分析平台中的应用与挑战
MK分析平台通常需要处理TB/PB级的实时数据流,并支撑数百甚至上千个并发即席查询。MergeTree的读路径设计完美契合了此类需求:
- 优势:
- 极致压缩与低I/O:列存+压缩,配合索引剪枝,使得单次查询的物理I/O量极小。
- 高吞吐分析:向量化执行引擎充分利用现代CPU能力,适合聚合、扫描类分析查询。
- 可预测的性能:稀疏索引结构稳定,查询性能与数据量增长呈亚线性关系。
- 挑战与优化:
- 主键设计:主键的顺序直接影响索引剪枝效率。在MK平台中,需根据最频繁的查询模式(如
user<em>id, event</em>time)设计主键,将高频过滤字段放在前面。
- 索引粒度调优:
index_granularity需要权衡。更小的粒度能提升点查精度但会增加索引大小;更大的粒度能提升扫描吞吐但可能读取更多无效数据。在偏重宽表扫描的场景,可适当调大。
- 数据排序(ORDER BY)优化:MergeTree的数据在片段内按主键排序。确保数据写入时尽可能有序,可以生成更大的数据片段,减少片段数量,从而提升合并效率并减少读查询时需要打开的碎片文件数。
- 应对“乱序”写入:实时流写入难免乱序。ClickHouse提供了
ReplacingMergeTree、CollapsingMergeTree等变种,以及FINAL关键字,但需在查询时注意语义一致性。在平台层面,可能需要缓冲或微批处理来提升写入局部性。
- 缓存策略:利用
mark<em>cache、uncompressed</em>cache等,将频繁访问的索引标记和解压后数据块缓存在内存中,对于重复查询模式(如仪表盘)性能提升显著。
四、与展望
ClickHouse MergeTree 引擎的读路径,通过稀疏索引、列式存储、向量化执行等多重技术组合,构建了一条从磁盘到CPU的“数据高速公路”,这正是其能在MK等大规模分析平台中担当重任的原因。
深入理解其源码机制(如MergeTreeReader、MergeTreeRangeReader等核心类),不仅有助于我们更好地使用ClickHouse,更能为平台级的性能调优、故障排查提供根本性的指导。随着硬件发展(如NVMe SSD、持久内存)和查询模式的演化,MergeTree的读路径优化,如更智能的预取、自适应索引粒度、与计算下推的更深度结合等,仍将是提升分析平台极限性能的关键方向。